
[update: the data.world connector is now available in beta, as a preview feature in Power BI. However, this post is relevant in case you’d like to manage what you retrieve through your own code]
data.world is a website promising “open, secure, social, and linked” data sets. Using external data sets is a great way to learn, benchmark against competition or industry, and spark new ideas. With this tutorial, we’ll show you how to use their R Library in Power BI to retrieve and build a simple visual of some basic information.
To begin, you’ll want to install their R SDK. The short version here is to open your favorite R IDE, and enter:
install.packages("data.world")
After, get your API key from data.world by going to advanced settings in your data.world profile. Open your favorite IDE back up, and make sure to save the API key so the library will have it on open in the future:
api_key_config <- data.world::save_config("API KEY") data.world::set_config(api_key_config)
Find your favorite data set, and we can begin. For this exercise, I’ll choose the Original Six Hockey data set.
The author of this set is scuttlemonkey, the name is original-six-hockey, and the CSV I want in particular is DET-captains, a list of all captains of the Detroit Red Wings. This gives us everything we need.
In Power BI, choose ‘Get Data’ and then find ‘R Script’

Enter the following code into the window:
library(data.world)
detroit.captains <- query(qry_sql("SELECT * FROM `DET-captains`"), dataset = "scuttlemonkey/original-six-hockey")
Hit submit, and in no time, you’ll see a preview of a data frame containing all the Detroit Red Wings captains in their history!
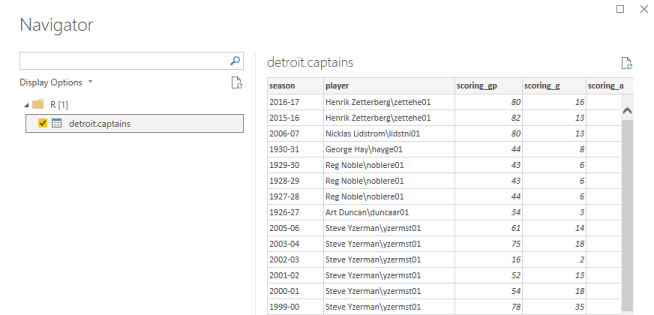
From here, we have a dataset available for us to analyze in whatever ways we need within Power BI.

With a data set analyzed, we can ask questions like:
What happened in the 2004-2005 season? (There was an NHL lockout)
Why are there two captains in 1980? (Reed Larson and Errol Thompson split captainship that season, with Errol Thompson eventually being traded to the Pittsburgh Penguins)
